Machine Learning Model for Home Credit Default Risk
Welcome to the "Home Credit Default Risk" machine learning project! In this endeavor, we tackle a vital business problem – predicting whether an applicant for a home credit loan will be able to repay their debt.
- The Business Problem: This project revolves around a binary classification task: predicting if a client will face payment difficulties. We aim to assign a binary label: 1 for clients with potential payment issues (i.e., late payments on at least one of the first Y installments of the loan), and 0 for those who will manage their payments seamlessly. We'll evaluate the model's performance using the Area Under the ROC Curve (AUC-ROC), and our models will provide probabilities indicating the likelihood of a loan not being paid for each set of input data.
- About the Data: To accomplish this task, we'll work with the primary datasets: application_train_aai.csv and application_test_aai.csv. No need to fret about data acquisition; the necessary datasets will be automatically downloaded within the HomeCreditDefaultRisk.ipynb notebook.
- Technical Aspects: You'll primarily interact with the Jupyter notebook, HomeCreditDefaultRisk.ipynb, which serves as your guide throughout the project. The technologies employed are:
- Pythonfor data ingestion and manipulation from CSV files
- Pandasfor data ingestion and manipulation from CSV files
- Scikit-learnfor feature engineering and model development
- Matplotliband Seaborn for data visualizations
- Jupyter Notebooksfor an interactive and insightful exploration of the project
- Installation:Setting up the project is a breeze. We've provided a requirements.txt file with all the necessary Python libraries. To install these dependencies, simply execute the following command:
$ pip install -r requirements.txt
(Note: We highly recommend creating a virtual environment for your project to avoid any potential conflicts with other Python packages.)
- Code Style:Maintaining a consistent code style is crucial for code readability and efficient collaboration. In this project, we employ Black and isort for automated code formatting. You can effortlessly format your code with the following command:
$ isort --profile=black . && black --line-length 88 .
(For further insights into Python code style and best practices, please refer to resources like The Hitchhiker’s Guide to Python: Code Style and Google Python Style Guide)
- Tests:Ensuring code correctness and robustness is a paramount concern. We've included unit tests that you can execute to verify that the code meets the minimum requirements of correctness. To run these tests, simply execute:
$ pytest tests/
(If you're interested in enhancing your knowledge of testing Python code, check out Effective Python Testing With Pytest and The Hitchhiker’s Guide to Python: Testing Your Code.)
Folder Architecture
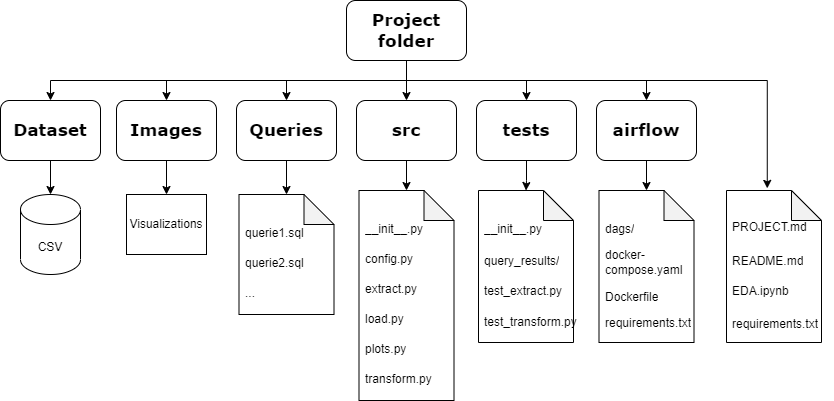
Data Structure
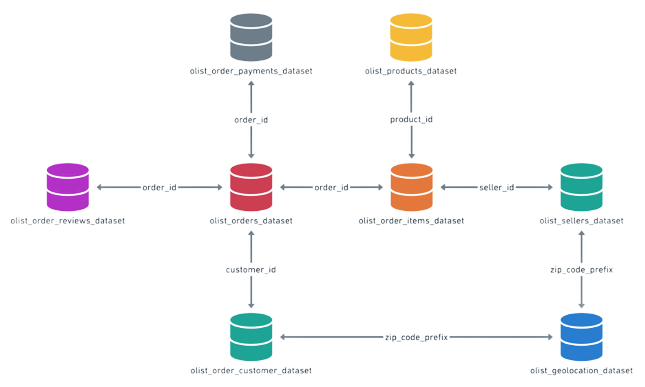
Here I compiled all the ETL python files and all the queries into a single Jupyter Notebook
To access the full project, please visit my GitHub repository
In this repository, you will find the ETL written in Python, the SQL queries, the plots created with Matplotlib and Seaborn, the tests using Pytest, and the Airflow orchestration, which includes the DAG creation and the Docker container.Git Hub
Technologies:
- Pandas
- Numpy
- Apache Airflow
- Docker
- SQL
- SQLite
- Matplotlib and Seaborn
- pytest
- DBeaver